3 Bayesian computation
To summarize what we saw in Chapter 2, after setting suitable priors on the models and parameters, we obtained two posterior distributions of interest: the posterior distribution on the models \(p(\boldsymbol{\gamma} \mid \mathbf{y})\) and the BMA posterior on parameters \(p(\boldsymbol{\theta} \mid \mathbf{y})\), where \(\boldsymbol{\theta}= \{ \boldsymbol{\theta}_\gamma \}_{\gamma \in \Gamma}\) is the collection of parameters from all models. These are given by \[\begin{align} p(\boldsymbol{\gamma} \mid \mathbf{y})&= \frac{p(\mathbf{y} \mid \boldsymbol{\gamma})p(\boldsymbol{\gamma})}{p(\mathbf{y})} \propto p(\mathbf{y} \mid \boldsymbol{\gamma}) p(\boldsymbol{\gamma}) \nonumber \\ p(\boldsymbol{\theta} \mid \mathbf{y})&= \sum_{\gamma} p(\boldsymbol{\theta} \mid \boldsymbol{\gamma},\mathbf{y}) p(\boldsymbol{\gamma} \mid \mathbf{y}). \nonumber \end{align}\]
Therefore, one needs to compute \[\begin{align} & p(\mathbf{y} \mid \boldsymbol{\gamma})= \int p(\mathbf{y} \mid \boldsymbol{\theta}_\gamma, \boldsymbol{\gamma}) p(\boldsymbol{\theta}_\gamma \mid \boldsymbol{\gamma}) d\boldsymbol{\theta}_\gamma \nonumber \\ & p(\boldsymbol{\theta}_\gamma \mid \boldsymbol{\gamma}, \mathbf{y})= \frac{p(\mathbf{y} \mid \boldsymbol{\theta}_\gamma, \boldsymbol{\gamma}) p(\boldsymbol{\theta}_\gamma \mid \boldsymbol{\gamma})}{p(\mathbf{y} \mid \boldsymbol{\gamma})}. \nonumber \end{align}\]
We next overview some basic notions in Bayesian computation, see for example Gamerman and Lopes (2006) for a lengthier yet accessible introduction to many of the ideas discussed here, and Brooks et al. (2011) for a handbook covering a range of applied MCMC topics.
Outside simple cases such as linear regression or additive non-linear regression with Gaussian errors (Section 6), neither \(p(\mathbf{y} \mid \boldsymbol{\gamma})\) nor \(p(\boldsymbol{\theta}_\gamma \mid \boldsymbol{\gamma},\mathbf{y})\) have closed-form. A fairly fast and often quite accurate approximation is to use Normal/Laplace approximations, and these are discussed in Section 3.1.
The other main challenge is that, even if \(p(\mathbf{y} \mid \boldsymbol{\gamma})\) can be quickly computed, one may need to explore a prohibitively large model space.
Markov Chain Monte Carlo (MCMC) methods, discussed in Section 3.2), are the standard tool for this task.
Another possible strategy is to use variational inference methods adapted to the model selection setting, e.g. as done by Carbonetto and Stephens (2012) for regression problems.
The main caveat of variational methods are that they can significantly under-estimate uncertainty, and this is particularly critical for model selection and hypothesis testing problems. We illustrate this issue with two examples, where we compare MCMC to the variational approach of Carbonetto and Stephens (2012) implemented in package varbvs.
Example 3.1 shows a simulated data where variational inference underestimates model uncertainty, in that posterior inclusion probabilities are closer to 0 or 1 than for MCMC. Other than that, there is a reasonable agreements between the results from both methods.
Example 3.2 analyzes a colon cancer gene expression dataset from Calon et al. (2012), and there the variational and MCMC solutions differ significantly. In fact, the findings from the latter align better with the expected biology.
These examples motivate the use of MCMC for model search, as described in Section 3.2.
Example 3.1 We simulate a dataset with \(n=100\), \(p=200\) standard Gaussian covariates with pairwise correlations equal to 0.5. Only the last 4 regression are truly non-zero.
Code
We obtain MCMC estimates of BMA posterior means \(E(\beta_j \mid \mathbf{y})\) and posterior inclusion probabilities \(P(\beta_j \neq 0 \mid \mathbf{y})\) using modelSelection, and analogous variational estimates using varbvs. For illustration, in both cases we set a Binomial model prior with 0.1 prior inclusion probability, and a Gaussian shrinkage prior on parameters with unit variance.
Code
Code
Code
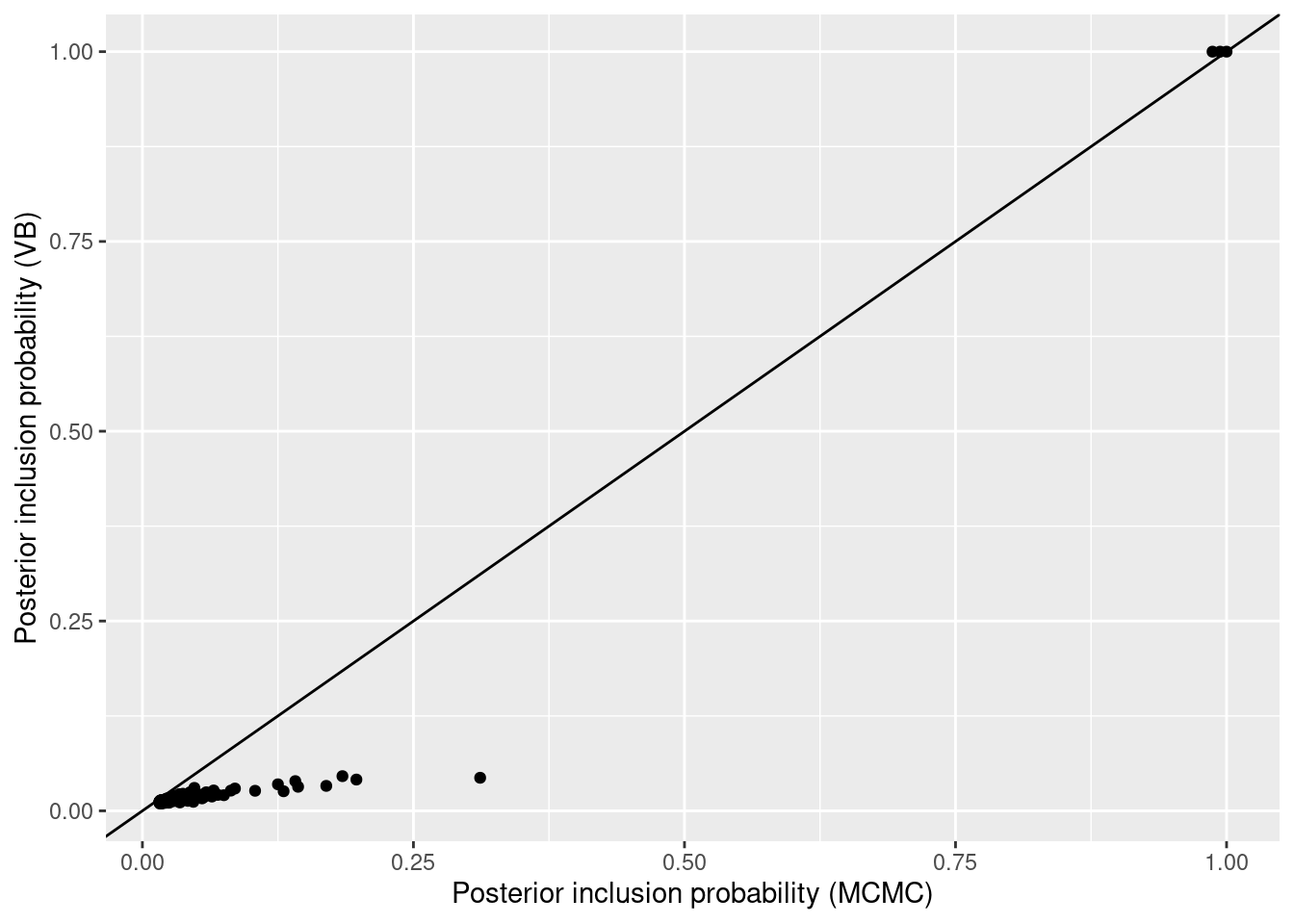
Comparing \(P(\beta_j \neq 0 \mid \mathbf{y})\) between the two methods shows that they both identify the same set of high posterior inclusion probability variables: 3 have posterior inclusion probability > 0.9, and the associated data-generating \(\beta_j \neq 0\) for the 3 of them. However, the plot below that the variational inclusion probabilities are much closer to 0 for the remaining variables than their MCMC counterparts.
## beta postmean_mcmc pip_mcmc postmean_vb pip_vb
## x197 -0.6666667 -0.5854735 0.9870538 -0.5863076 0.9999994
## x199 0.6666667 0.6005244 0.9940094 0.6037434 1.0000000
## x200 1.0000000 1.2487064 1.0000000 1.2422280 1.0000000Code
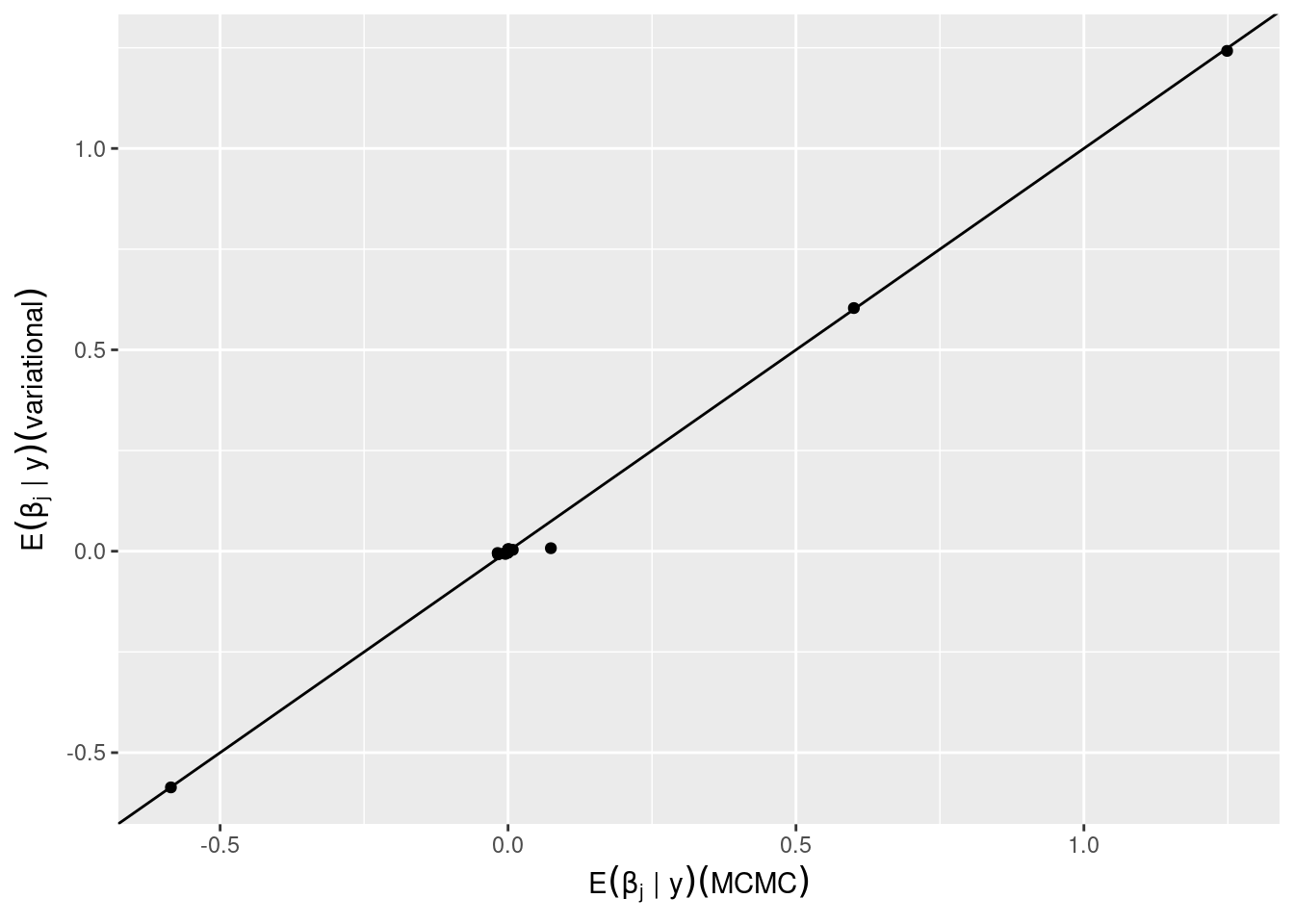
We may also compare the BMA posterior means, in this example the variational and MCMC solutions are similar.
Code
Example 3.2 Calon et al. (2012) compared mice where gene TGFB was silenced to mice where it was not, found a list of 172 genes that were associated to TGFB, and showed that TGFB plays a crucial role in colon cancer progression. We take their data as subsequently analyzed in Rognon-Vael and Rossell (2025), which contains the expression of TGFB plus \(p=1,000\) genes (including the 172 genes from the mouse list) for \(n=262\) human patients. The goal is to regress TGFB on the other genes, which is of interest given the importance of TGFB in colon cancer progression. We also wish to assess whether the 172 genes identified from the mouse study are more likely to be associated to TGFB, as would be expected biologically and as shown in Rognon-Vael and Rossell (2025). Both TGFB and the other genes were standardized to zero mean and unit variance.
We load the data and use modelSelection for MCMC-based inference and varbvs for variational inference.
In both we use a Gaussian shrinkage prior on parameters with unit variance.
In varbvs we use a Binomial model prior with prior inclusion probabilty 0.1, and for convenience in modelSelection we use a Beta-Binomial model prior as it runs faster than the Binomial prior, but our subsequent discussion continues to apply if one uses the Binomial prior as well.
Code
Code
Code
Code
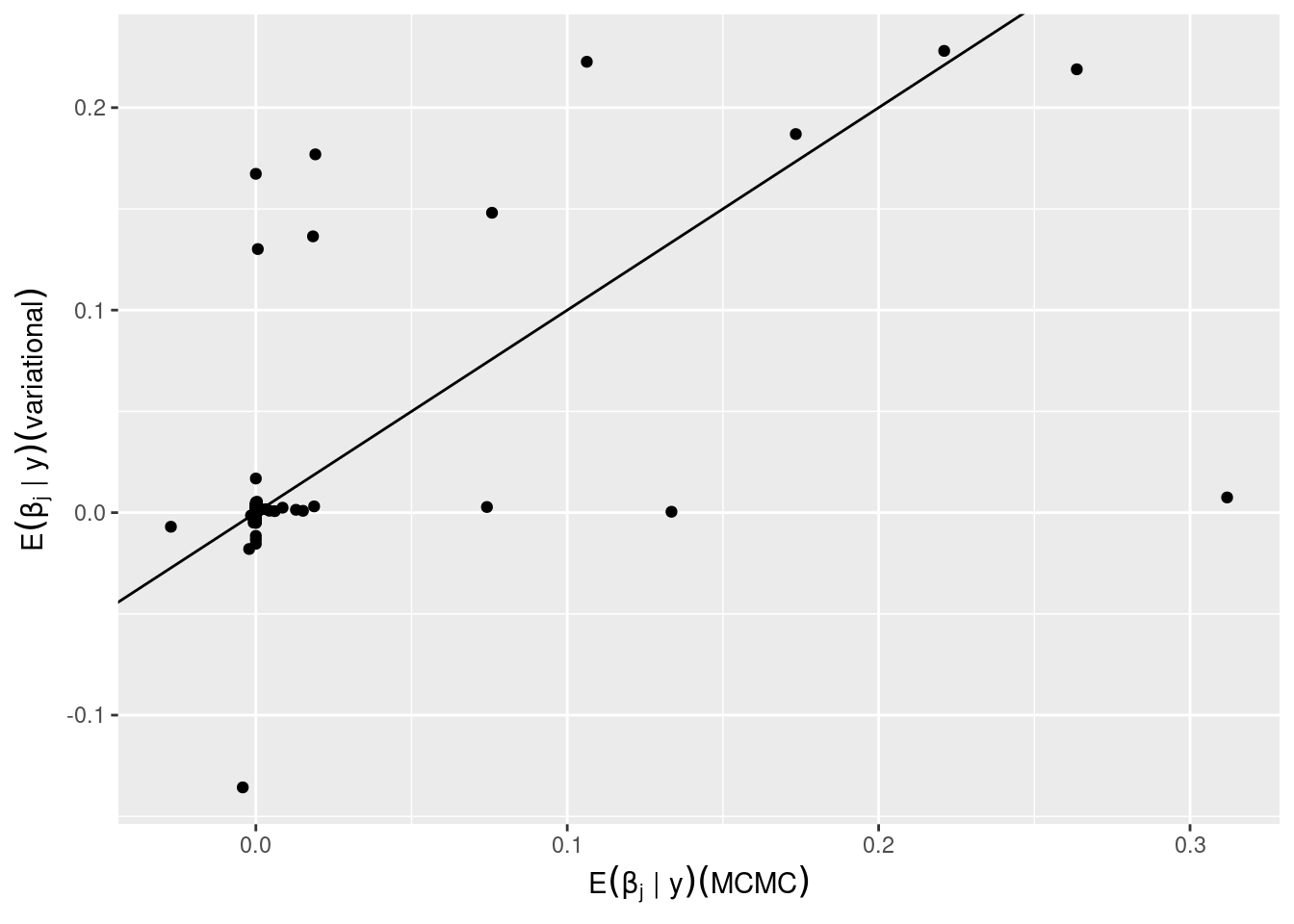
The marginal posterior probabilities estimated from both methods differ drastically: the variational estimates are much closer to 0 or 1 than those from MCMC, significantly underestimating model uncertainty. The BMA parameter estimates are also very different.
Code
ggplot(df, aes(x=pip_mcmc, y=pip_vb)) +
geom_point() +
geom_abline() +
labs(x='Posterior inclusion probability (MCMC)',
y='Posterior inclusion probability (VB)')
ggplot(df, aes(x=postmean_mcmc, y=postmean_vb)) +
geom_point() +
geom_abline() +
labs(x= bquote(E(beta[j] ~ "|" ~ y) (MCMC)),
y= bquote(E(beta[j] ~ "|" ~ y) (variational)))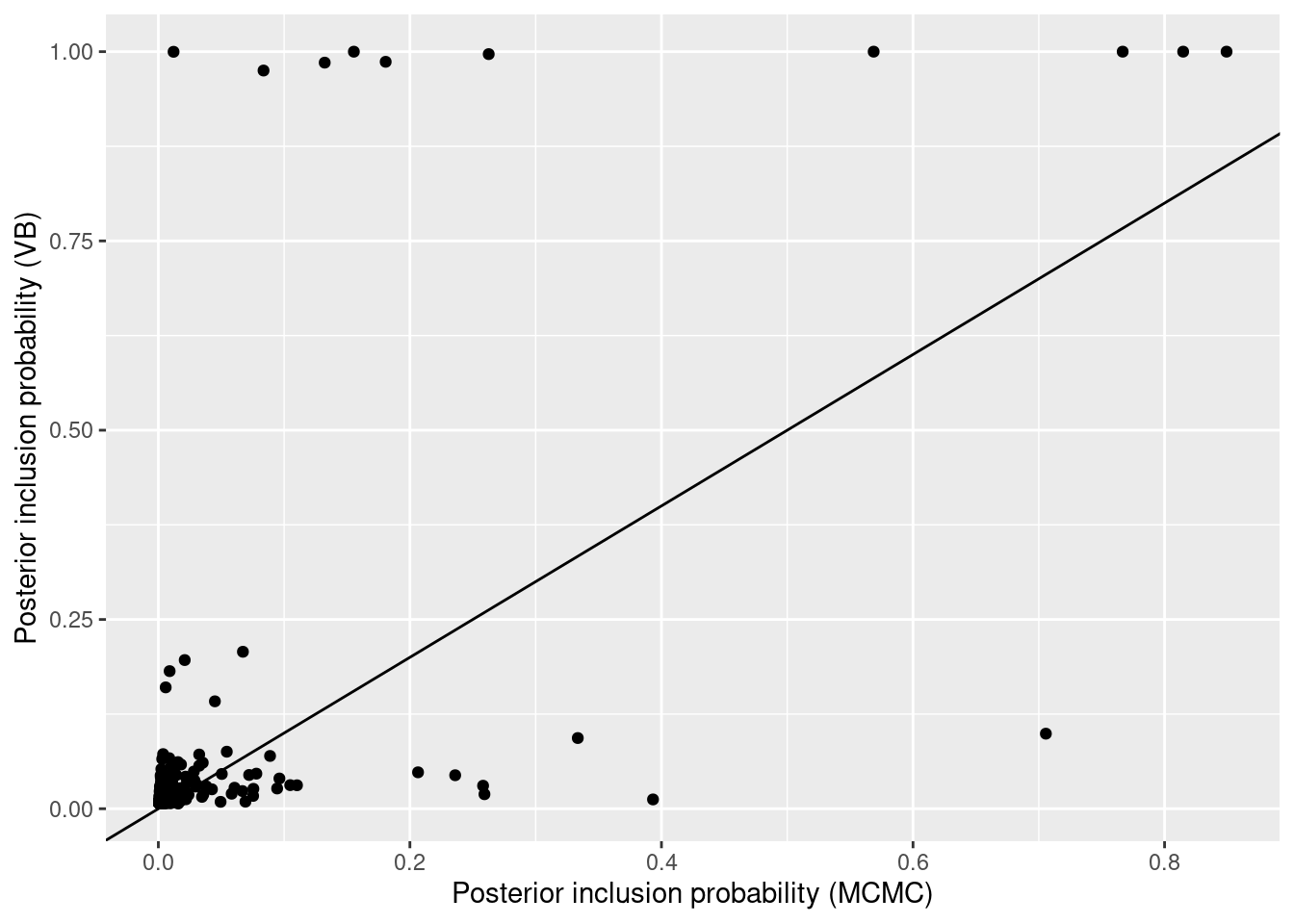
From purely a Bayesian point of view this shows variational inference may provide a poor approximation to the desired posterior. This is different from saying that the exact Bayesian solution provides better inference than the variational one, in terms of detecting the genes that are truly associated with TGFB. As an additional check in this direction, we compare the average posterior inclusion probability between genes that were inside/outside the mouse list. For the MCMC estimates there is a big difference, roughly 0.023/0.007 = 3.3, which aligns with what’s expected biologically. For the variational estimates the difference is much smaller.
## # A tibble: 2 × 3
## inshort `mean(pip_mcmc)` `mean(pip_vb)`
## <lgl> <dbl> <dbl>
## 1 FALSE 0.00736 0.0210
## 2 TRUE 0.0244 0.03133.1 Marginal likelihoods and model-specific posteriors
The marginal likelihood in (2.2) has a closed-form expression in some instances, mainly regression with Gaussian errors (e.g., linear regression, non-linear additive regression) with conjugate parameter priors. Recall that the marginal likelihood for model \(\boldsymbol{\gamma}\) is \[\begin{align*} p(\mathbf{y} \mid \gamma)= \int p(\mathbf{y} \mid \boldsymbol{\theta}_\gamma, \gamma) p(\boldsymbol{\theta}_\gamma \mid \gamma) d\boldsymbol{\theta}_\gamma. \end{align*}\]
Outside these special cases, a numerical approximation is required.
The modelSelection function implements some such approximations, and their use can be specified with the argument method.
For example, set method=='Laplace' to use Laplace approximations, described next.
If method is not specified, modelSelection selects a sensible default.
Laplace approximations are fairly computationally efficient, and also highly accurate as \(n\) grows (Kass, Tierney, and Kadane 1990). Consider the integral \[\begin{align} \int e^{f(\boldsymbol{\theta}_\gamma)} d\boldsymbol{\theta}_\gamma \nonumber \end{align}\] where \(\boldsymbol{\theta}_\gamma \in \mathbb{R}^{d_\gamma}\) and \(d_\gamma= \mbox{dim}(\boldsymbol{\theta}_\gamma)\) is the number of parameters. Let \(\hat{\boldsymbol{\theta}}_\gamma= \arg\max_{\boldsymbol{\theta}_\gamma} f(\boldsymbol{\theta}_\gamma)\) and \(H_\gamma(\boldsymbol{\theta})= - \nabla^2 f(\boldsymbol{\theta}_\gamma)\). The Laplace approximation is \[\begin{align} \int e^{f(\boldsymbol{\theta}_\gamma)} d\boldsymbol{\theta}_\gamma \approx \int e^{f(\hat{\boldsymbol{\theta}}_\gamma)} e^{- \frac{1}{2} (\hat{\boldsymbol{\theta}}_\gamma - \boldsymbol{\theta}_\gamma)^T H(\hat{\boldsymbol{\theta}}_\gamma) (\hat{\boldsymbol{\theta}}_\gamma - \boldsymbol{\theta}_\gamma)} d\boldsymbol{\theta}_\gamma = \frac{e^{f(\hat{\boldsymbol{\theta}}_\gamma)} (2 \pi)^{d_\gamma/2}}{|H_\gamma(\hat{\boldsymbol{\theta}}_\gamma)|^{\frac{1}{2}}}. \nonumber \end{align}\]
In our Bayesian model selection context, the Laplace approximation to the marginal likelihood of model \(\boldsymbol{\gamma}\) is \[\begin{align} \hat{p}(\mathbf{y} \mid \boldsymbol{\gamma})= \frac{p(\mathbf{y} \mid \hat{\boldsymbol{\theta}}_\gamma, \boldsymbol{\gamma}) p(\hat{\boldsymbol{\theta}}_\gamma) (2 \pi)^{d_\gamma/2}}{|H_\gamma(\hat{\boldsymbol{\theta}}_\gamma)|^{\frac{1}{2}}}. \nonumber \end{align}\]
Laplace approximations require finding the posterior mode \(\hat{\boldsymbol{\theta}}_\gamma\) (alternatively, the MLE is sometimes used) and the hessian of the log-posterior density at \(\hat{\boldsymbol{\theta}}_\gamma\). Both these quantities can be found quickly for models that feature a few parameters, but the calculations get cumbersome when:
One considers many models, i.e. one must repeat the optimization exercise many times
Some models that feature many parameters have high posterior probability, and hence they’re visited often by an MCMC model search algorithm
The sample size \(n\) is large, so evaluating gradients (or hessians) to obtain \(\hat{\boldsymbol{\theta}}_\gamma\) gets costly.
An alternative is to use approximate Laplace approximations (ALA) (D. Rossell, Abril, and Bhattacharya 2021), which are available by using method=='ALA'.
Briefly, ALA approximates \(\hat{\boldsymbol{\theta}}_\gamma\) by taking a single Newton-Raphson step from an initial estimate \(\hat{\boldsymbol{\theta}}_\gamma^{(0)}\). By default \(\hat{\boldsymbol{\theta}}_\gamma^{(0)}= 0\) is taken, see D. Rossell, Abril, and Bhattacharya (2021) for a study of the theoretical properties of this choice. Alternatively, in modelSelection one may provide other
\(\hat{\boldsymbol{\theta}}_\gamma^{(0)}\) with the argument initpar.
Laplace approximations are based on a simple Taylor expansion of \(f(\boldsymbol{\theta}_\gamma)\) around \(\hat{\boldsymbol{\theta}}_\gamma\). This expansion also gives a Gaussian approximation to \(p(\boldsymbol{\theta}_\gamma \mid \gamma, \mathbf{y})\). Specifically, \[\begin{align} \hat{p}(\boldsymbol{\theta}_\gamma \mid \boldsymbol{\gamma}, \mathbf{y}) \approx N \left(\boldsymbol{\theta}_\gamma; \hat{\boldsymbol{\theta}}_\gamma; H^{-1}(\hat{\boldsymbol{\theta}}_\gamma) \right), \nonumber \end{align}\] where \(\hat{\boldsymbol{\theta}}_\gamma= \arg\max_{\theta_\gamma} f(\boldsymbol{\theta}_\gamma)\)
3.2 Model search
MCMC algorithms provide a basic workhorse for Bayesian model selection when one cannot exhaustively enumerate the set of possible models. These algorithms have proven surprisingly effective in practice, particularly when posterior model probabilities \(p(\boldsymbol{\gamma} \mid \mathbf{y})\) concentrate on sparse models, and when one can quickly evaluate the marginal likelihood \(p(\mathbf{y} \mid \boldsymbol{\gamma})\) (or approximate it, as discussed in Section 3.1) and prior probability \(p(\boldsymbol{\gamma})\) for each model \(\boldsymbol{\gamma}\). MCMC is also useful to approximate the Bayesian model averaging (BMA) posterior \(p(\boldsymbol{\theta} \mid \mathbf{y})\), and typically this has little extra cost once one has already approximated \(p(\boldsymbol{\gamma} \mid \mathbf{y})\).
The main idea of MCMC is to approximate the posterior distribution on the models, \(p(\boldsymbol{\gamma} \mid \mathbf{y})\), by obtaining a sufficiently large number of samples from it. If one has \(B\) (typically dependent) samples \(\boldsymbol{\gamma}_1,\ldots,\boldsymbol{\gamma}_B\) from \(p(\boldsymbol{\gamma} \mid \mathbf{y})\), one can easily estimate any quantity of interest. For example, the posterior probability of any given model \(\boldsymbol{\gamma}'\) can be estimated by the proportion of samples where \(\boldsymbol{\gamma}'\) was observed, i.e. \[\begin{align*} \hat{p}(\boldsymbol{\gamma} \mid \mathbf{y})= \frac{1}{B} \sum_{b=1}^B \mbox{I}(\boldsymbol{\gamma}^{(b)}= \boldsymbol{\gamma}). \end{align*}\] Another typical example in variable selection is when \(\boldsymbol{\gamma}=(\boldsymbol{\gamma}_1,\ldots,\boldsymbol{\gamma}_p)\) and \(\gamma_j= \mbox{I}(\beta_j \neq 0)\), then a naive estimator for marginal posterior inclusion probabilities is \[\begin{align*} \hat{P}(\gamma_j = 1 \mid \mathbf{y}) = \frac{1}{B} \sum_{b=1}^B \mbox{I}(\gamma_j^{(b)} = 1). \end{align*}\]
There are many possible MCMC algorithms that one may use (i.e. with \(p(\boldsymbol{\gamma} \mid \mathbf{y})\) as the unique stationary distribution), and the art is to choose one that returns accurate approximations in as little time as possible. A classical strategy in the variable selection setting is to use Gibbs sampling (Madigan and Raftery (1994), Hoeting et al. (1999)), which consists in adding/excluding one covariate at a time. Such updates are sometimes referred to as birth-death moves. Yang, Wainwright, and Jordan (2016) showed that, if certain sparsity assumptions hold, then a birth-death-swap algorithm can search the model space at polynomial cost in \(p\) (more precisely, they prove polynomial bounds on the algorithm’s spectral gap). Zhou et al. (2022) proposed a locally informed thresholded algorithm (LIT) that’s theoretically appealing in being scalable to high dimensions, also under suitable sparsity conditions that guarantee sufficient posterior concentration. See also Chang and Zhou (2025) for more recent algorithms leading to dimension-free mixing. In practice simple Gibbs sampling works remarkably well, in our experience it usually attains a similar numerical accuracy when it’s run for the same clock time as birth-death-swap and LIT.
Section 3.3 gives a brief introduction to MCMC and its cornerstone algorithm, Metropolis-Hastings (MH). We then discuss Gibbs sampling in Section 3.4, locally-informed proposals in Section 3.5 and Hamiltonian Monte Carlo in Section 3.6, all of which are particular cases of the MH algorithm. The actual adaptations of these algorithms to our model selection settings of interest are given in Chapters 5, 6 and 9.1 for generalized linear models, generalize additive models and Gaussian graphical models respectively.
Before proceeding, we illustrate the main idea with a fun analogy (which motivated this book’s cover) where one is searching for beer. This is also a wink to my friend Gareth Roberts, who has uncanny beer-searching abilities (besides his more famously known MCMC-related abilities).
Example 3.3 Suppose that you are inside of a bar that has an extremely large number of beer taps. As a welcome present you’re given a glass of beer, but you’re not told the brand or the name of the beer. You like that beer so much that you set out to find out which beer it is. To do so, you need to sample beers from different taps, and score them according to how similar they are to your target beer. The picture below illustrates the situation.

Figure 3.1: Beer search as a high-dimensional model selection problem
In this analogy the beer that you first tasted are the data \(\mathbf{y}\), the taps are possible models from where the data may have originated, and the score that you give to each sampled tap is \(s(\boldsymbol{\gamma})= p(\mathbf{y} \mid \boldsymbol{\gamma}) p(\boldsymbol{\gamma})\), i.e. it’s proportional to the model’s posterior probability. Since there are too many possible taps (models), you cannot try them all. Instead, you decide to randomly explore beer taps: you will sample a total of \(B\) taps, you may sample a tap more than once, and you want to sample each tap with probability proportional to its score \(s(\boldsymbol{\gamma})\).
A possible MCMC algorithm for this task is as follows. You start your search by tasting an initial tap \(\boldsymbol{\gamma}^{(0)}\) (possibly randomly chosen). You set the iteration counter to \(b=1\) and then choose the next beer randomly, as follows.
Propose a new beer tap \(\boldsymbol{\gamma}^*\) uniformly at random among the neighbors of \(\boldsymbol{\gamma}^{(b-1)}\), denoted by \(\mathcal{N}(\boldsymbol{\gamma}^{(b-1)})\). For simplicity, we assume that all taps have the same number of neighbors.
Set the next tap to \(\boldsymbol{\gamma}^{(b)}=\boldsymbol{\gamma}^*\) with probability \(s(\boldsymbol{\gamma}^*)/s(\boldsymbol{\gamma}^{(b-1)})\) (if this quantity is \(>1\), then we move to \(\boldsymbol{\gamma}^*\) for sure). Otherwise, stay at the current tap, i.e. \(\boldsymbol{\gamma}^{(b)}= \boldsymbol{\gamma}^{(b-1)}\).
After these two steps, you set \(b=b+1\) and go back to Step 1, until \(b=B\). This strategy defines a Markov chain: the probability distribution for \(\boldsymbol{\gamma}^{(b)}\) depends only on the previous tap \(\boldsymbol{\gamma}^{(b-1)}\). Intuitively, the algorithm moves towards better beers (we move to \(\boldsymbol{\gamma}^*\) for sure when its score is better than the current \(\boldsymbol{\gamma}^{(b-1)}\)), but it can also occasionally move to worse beers and this is why there’s some hope of not getting trapped in local modes (at least, not forever).
The magic is that, under mild conditions, this Markov chain converges to its unique stationary distribution, and the latter is \(p(\boldsymbol{\gamma} \mid \mathbf{y})\). This example is purely meant as an illustration: this simple algorithm is called random walk Metropolis-Hastings (RWMH) and we do not expect this to be particularly efficient, it’s just an easy one to explain and to implement in your computer. See Section 3.3 for further details, and Exercise 3.1 to show that this algorithm is an instance of the Metropolis-Hastings algorithm.
For fun, we show a numerical illustration. Consider a posterior \(p(\boldsymbol{\gamma} \mid \mathbf{y})\) on the 10 x 10 lattice, i.e. where \(\boldsymbol{\gamma}=(\gamma_1,\gamma_2) \in \{1,2,\ldots,10\}^2\). First consider a \(p(\boldsymbol{\gamma} \mid \mathbf{y})\) that has a single mode at \({\bf m}=(10,10)\) and whose log mass function depends on the Euclidean distance to the mode. Specifically, \[ p(\boldsymbol{\gamma} \mid \mathbf{y}) \propto \exp{- 0.6 ||\boldsymbol{\gamma} - {\bf m}||_2}, \] where \(|| \cdot ||_2\) is the Euclidean distance. The animation below shows the first 200 MCMC iterations of the RWMH algorithm, initialized at a random \(\boldsymbol{\gamma}^{(0)}\).
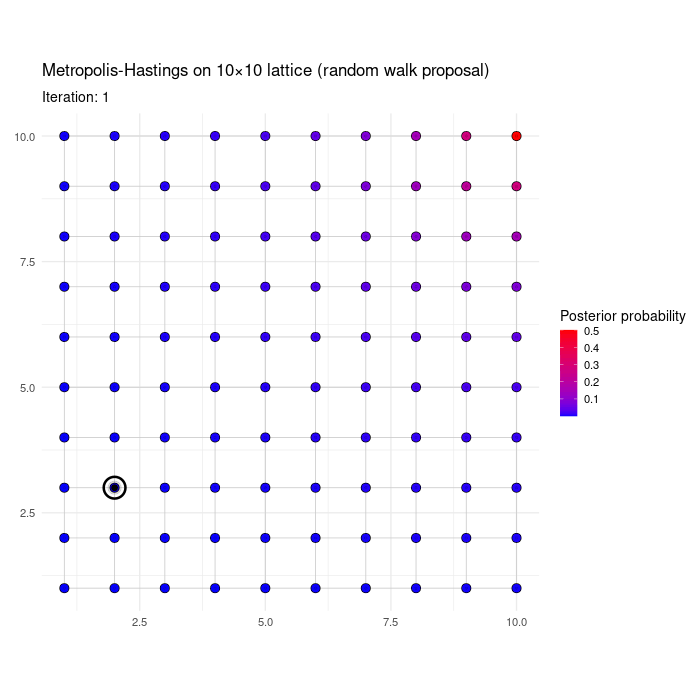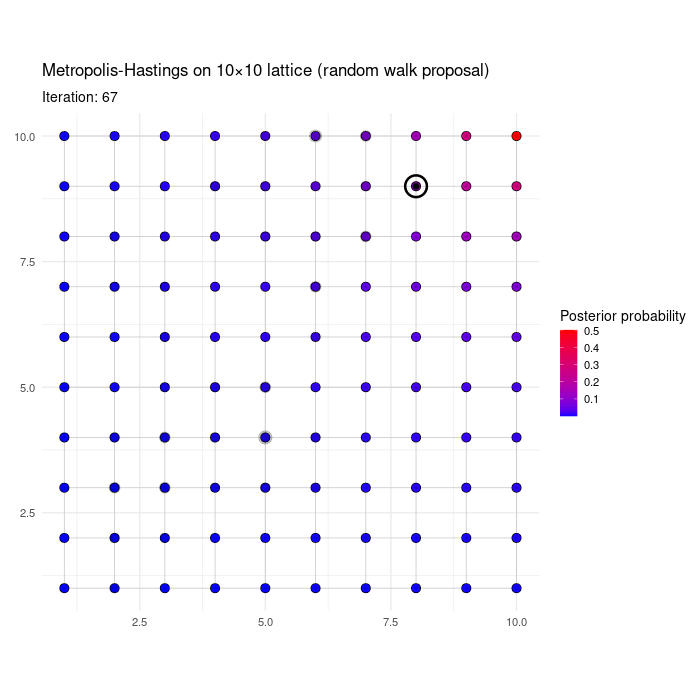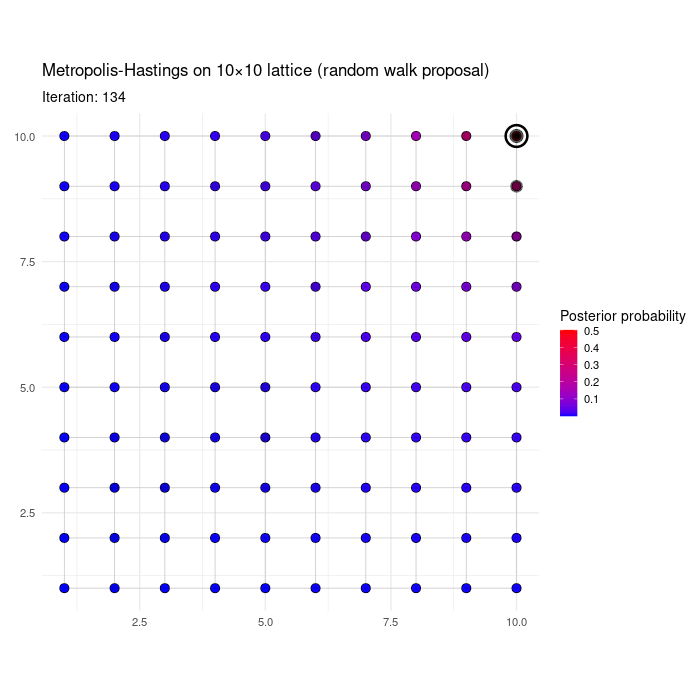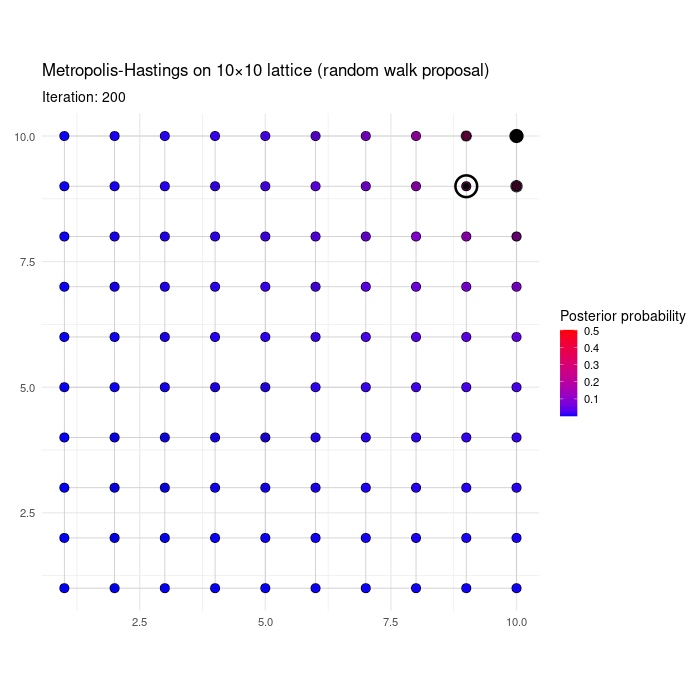
Figure 3.2: RWMH on a bimodal distribution on the lattice
The next table shows \(\hat{p}(\boldsymbol{\gamma} \mid \mathbf{y})\) gives by the proportion of iterations spent in each node after 2,000 iterations, for the 10 highest posterior probability \(\boldsymbol{\gamma}\)’s. The approximation is not perfect, but it’s reasonably accurate.
| \(\gamma_1\) | \(\gamma_2\) | \(p(\boldsymbol{\gamma} \mid \mathbf{y})\) | \(\hat{p}(\boldsymbol{\gamma} \mid \mathbf{y})\) |
|---|---|---|---|
| 10 | 10 | 0.1588 | 0.1560 |
| 9 | 10 | 0.0872 | 0.0755 |
| 10 | 9 | 0.0872 | 0.0900 |
| 9 | 9 | 0.0680 | 0.0560 |
| 8 | 10 | 0.0478 | 0.0280 |
| 10 | 8 | 0.0478 | 0.0450 |
| 8 | 9 | 0.0415 | 0.0340 |
| 9 | 8 | 0.0415 | 0.0250 |
| 8 | 8 | 0.0291 | 0.0195 |
| 7 | 10 | 0.0262 | 0.0240 |
As a second and more challenging example, consider now a posterior with two modes at \(\bf{m}_1= (1,1)\) and \(\bf{m}_2= (10,10)\). Specifically, \[ p(\boldsymbol{\gamma} \mid \mathbf{y}) \propto \sum_{j=1}^2 0.5 \exp\left\{ - 0.6 ||\boldsymbol{\gamma} - {\bf m}_j||_2 \right\}. \]
The animation below shows the first 200 iterations, and the subsequent table \(\hat{p}(\boldsymbol{\gamma} \mid \mathbf{y})\) after 2,000 iterations, for the 10 top models. Despite the fact that RWMH now has a harder time to transition from one mode to the other, the approximation is still reasonably accurate. If the posterior were more concentrated around each mode however, RWMH would not do a good job at exploring the space (like any other algorithm based on local moves). Fortunately, in Bayesian model selection the posterior distribution concentrates on a small set of models as \(n \to \infty\), and often (but not always) these models are contiguous in the model space. When this is the case, MCMC can be a very efficient tool.
Figure 3.3: RWMH on a bimodal distribution on the lattice
| \(\gamma_1\) | \(\gamma_2\) | \(p(\boldsymbol{\gamma} \mid \mathbf{y})\) | \(\hat{p}(\boldsymbol{\gamma} \mid \mathbf{y})\) |
|---|---|---|---|
| 1 | 1 | 0.0794 | 0.0850 |
| 10 | 10 | 0.0794 | 0.0560 |
| 1 | 2 | 0.0436 | 0.0430 |
| 2 | 1 | 0.0436 | 0.0470 |
| 9 | 10 | 0.0436 | 0.0350 |
| 10 | 9 | 0.0436 | 0.0345 |
| 2 | 2 | 0.0341 | 0.0340 |
| 9 | 9 | 0.0341 | 0.0290 |
| 1 | 3 | 0.0240 | 0.0250 |
| 3 | 1 | 0.0240 | 0.0315 |
3.3 MCMC basics
The basic building block for MCMC is the Metropolis-Hastings (MH) algorithm. We first present this algorithm, subsequently discuss Gibbs sampling as a particular case, and finally discuss Hamiltonian Monte Carlo as another particular case that has found particular success in applications. For fun, you can check an animation showing how different MCMC algorithms perform at https://chi-feng.github.io/mcmc-demo.
The goal is to sample from the posterior distribution \(p(\boldsymbol{\eta} \mid \mathbf{y})\), for some object of interest \(\boldsymbol{\eta}\). For example in BMS we may have \(\boldsymbol{\eta}=\boldsymbol{\gamma}\) and in BMA \(\boldsymbol{\eta}=(\boldsymbol{\theta}, \boldsymbol{\gamma})\). The MH algorithm starts from an initial \(\boldsymbol{\eta}=\boldsymbol{\eta}^{(0)}\) (which can in principle be arbitrary), and at iteration \(b\) uses a so-called proposal distribution \(h(\boldsymbol{\eta} \mid \boldsymbol{\eta}^{(b-1)})\) to generate an updated parameter value \(\boldsymbol{\eta}^{(b)}\).
Metropolis-Hastings algorithm.
Let \(B\) be the number of desired samples from \(p(\boldsymbol{\eta} \mid \mathbf{y})\).
Initialize \(\boldsymbol{\eta}^{(0)}\), set \(b=1\).
Propose \(\boldsymbol{\eta}^* \sim h(\boldsymbol{\eta} \mid \boldsymbol{\eta}^{(b-1)})\). With probability \(\min \{1, u\}\) set \(\boldsymbol{\eta}^{(b)}=\boldsymbol{\eta}^*\), else set \(\boldsymbol{\eta}^{(b)}=\boldsymbol{\eta}^{(b-1)}\), where \[\begin{align} u= \frac{p(\boldsymbol{\eta}^* \mid \mathbf{y})}{p(\boldsymbol{\eta}^{(b-1)} \mid \mathbf{y})} \frac{h(\boldsymbol{\eta}^{(b-1)} \mid \boldsymbol{\eta}^*)}{h(\boldsymbol{\eta}^* \mid \boldsymbol{\eta}^{(b-1)})} = \frac{p(\mathbf{y} \mid \boldsymbol{\eta}^*) p(\boldsymbol{\eta}^*)}{p(\mathbf{y} \mid \boldsymbol{\eta}^{(b-1)}) p(\boldsymbol{\eta}^{(b-1)})} \frac{h(\boldsymbol{\eta}^{(b-1)} \mid \boldsymbol{\eta}^*)}{h(\boldsymbol{\eta}^* \mid \boldsymbol{\eta}^{(b-1)})} \nonumber \end{align}\]
If \(b=B\) stop, else set \(b=b+1\) and go back to Step 2.
The short story is that under mild conditions, the Markov chain \((\boldsymbol{\eta}^{(b)})_{b \geq 0}\) defined by the MH algorithm converges to its unique stationary distribution. And, by construction, the stationary distribution is the posterior distribution \(p(\boldsymbol{\eta} \mid \mathbf{y})\) (this is guaranteed because of reversibility, see below).
The slightly longer story is as follows. Let \((\boldsymbol{\eta}^{(b)})_{b \geq 0}\) be a Markov chain on a (measurable) state space with transition kernel \(Q\). Two key properties, irreducibility and recurrence, guarantee the existence of a stationary distribution \(\pi\), meaning that \(Q \pi= \pi\) (Theorem 3.1). If the chain is also aperiodic, then the ergodic theorem (Theorem 3.2) gives an analog of the strong law of large numbers for Markov chains, and guarantees that the chain converges to its stationary distribution. We next state these definitions and results.
Definition 3.1 A chain is \(\psi\)-irreducible iff there is a measure \(\psi\) such that every set of positive \(\psi\)-measure is reachable from every starting point, in some number of steps with positive probability.
A \(\psi\)-irreducible chain is positive Harris recurrent iff starting from any \(\boldsymbol{\eta}\), the chain will visit every set of positive \(\psi\)-measure infinitely often, with probability 1.
Theorem 3.1 Existence & uniqueness of a stationary distribution.
Suppose that a Markov chain with kernel \(Q\) is \(\psi\)-irreducible and positive Harris recurrent. Then there exists a unique invariant probability \(\pi\) satisfying \(\pi Q=\pi\).
Theorem 3.2 Ergodic theorem (Harris / Meyn–Tweedie form). Suppose that a Markov Chain with kernel \(Q\) is \(\psi\)-irreducible, aperiodic and positive Harris recurrent. Then for any \(\pi\)-integrable function \(f\), \[ \frac{1}{B}\sum_{b=1}^{B} f(\boldsymbol{\eta}^{(b)})\ \xrightarrow{\text{a.s.}}\ \int f\,d\pi \qquad(B \to \infty), \] and the law of \(\boldsymbol{\eta}^{(b)}\) converges to \(\pi\) (often in total variation).
That is, to ensure that the chain converges to the desired \(p(\boldsymbol{\eta} \mid \mathbf{y})\), it suffices that the chain is irreducible, aperiodic and recurrent. Irreducibility is usually easy to satisfy, for example it holds when the proposal \(h()\) has full support, and also when the proposal makes local moves but the state space is connected, so that after several iterations one can move from any state to any other state (or its neighbourhood, for non-discrete spaces) with positive probability. Aperiodicity is also typically easy except in degenerate cases, for example usually MH has non-zero probability of staying at the same state and that’s enough to ensure aperiodicity. Proving recurrence can be harder for general state spaces, but for finite discrete spaces irreducibility automatically implies recurrence. For example, in Bayesian model selection \(\boldsymbol{\eta}=\boldsymbol{\gamma} \in \Gamma\) is a model and \(\Gamma\) is a possibly large, but finite, model space. More generally, recurrence can be proven using so-called drift + minorization techniques, under conditions on the tails of the target and proposal distributions.
Proving that the stationary distribution is \(p(\boldsymbol{\eta} \mid \mathbf{y})\) can be done by showing that, if \(\boldsymbol{\eta}^{(b)} \sim p(\boldsymbol{\eta} \mid \mathbf{y})\) then the distribution of \((\boldsymbol{\eta}^{(b)},\boldsymbol{\eta}^{(b+1)})\) is equal to that of \((\boldsymbol{\eta}^{(b+1)},\boldsymbol{\eta}^{(b)})\) (this is called reversibility), which implies that the marginal distribution of \(\boldsymbol{\eta}^{(b+1)}\) is equal to that of \(\boldsymbol{\eta}^{(b)}\) and hence that \(p(\boldsymbol{\eta} \mid \mathbf{y})\) is indeed a stationary distribution. See Exercise 3.2 for details.
3.4 Gibbs sampling
Gibbs sampling is a simple instance of the MH algorithm, yet it is surprisingly effective in many applications, including sampling from distributions in high-dimensional model spaces. Gibbs proceeds by proposing a new \(\boldsymbol{\eta}^*\) using full conditional posterior distributions, and accepting the proposal with probability 1 (Exercise 3.3). In its most basic form, Gibbs sampling proceeds as follows. Let \(B\) be the number of desired draws from \(p(\boldsymbol{\eta} \mid \mathbf{y})\) and \(\boldsymbol{\eta}_{-j}= \boldsymbol{\eta} \setminus \eta_j\) the vector \(\boldsymbol{\eta}\) after removing its \(j^{th}\) entry.
Gibbs sampling.
Initialize \(\boldsymbol{\eta}^{(0)}\), set \(b=1\).
Set \(\boldsymbol{\eta}^*=\boldsymbol{\eta}^{(b-1)}\). For \(j=1,\ldots,d\), update \(\eta_j^* \sim p(\eta_j \mid \boldsymbol{\eta}_{-j}^*,\mathbf{y})\).
Set \(\boldsymbol{\eta}^{(b)}= \boldsymbol{\eta}^*\). If \(b=B\) stop, else set \(b=b+1\) and go back to Step 2.
Popular variations of basic Gibbs include random scan Gibbs, where in Step 2 one draws the index \(j\) at random, and block Gibbs, where one samples a subset of parameters (rather than only one) given the remaining parameters.
The reason why Gibbs is convenient is that, in many cases, \(p(\eta_j \mid \boldsymbol{\eta}_{-j}^*,\mathbf{y})\) is easy to sample from. If this is not the case, one may use MH to sample from \(p(\eta_j \mid \boldsymbol{\eta}_{-j}^*,\mathbf{y})\), this is known as Metropolis-within-Gibbs. This can be particularly convenient in model selection settings when marginal likelihoods for models \(\boldsymbol{\gamma}\) are not available in closed-form. For example, let \(\boldsymbol{\gamma}=(\gamma_1,\ldots,\gamma_p)\) and \(\gamma_j= \mbox{I}(\beta_j \neq 0)\). If one cannot sample directly from \(p(\gamma_j \mid \boldsymbol{\gamma}_{-j}, \mathbf{y})\), one can instead propose \((\gamma_j^*, \beta_j^*) \sim h(\gamma_j, \beta_j \mid \boldsymbol{\gamma}_{-j}, \boldsymbol{\beta}_{-j}, \mathbf{y})\) and use MH as usual. One often can define \[\begin{align*} &h(\gamma_j \mid \boldsymbol{\gamma}_{-j}, \boldsymbol{\beta}_{-j}, \mathbf{y}) \approx p(\gamma_j \mid \boldsymbol{\gamma}_{-j}, \boldsymbol{\beta}_{-j}, \mathbf{y}) \\ &h(\beta_j \mid \boldsymbol{\gamma}, \boldsymbol{\beta}_{-j}, \mathbf{y}) \approx p(\beta_j \mid \boldsymbol{\gamma}, \boldsymbol{\beta}_{-j}, \mathbf{y}), \end{align*}\] and in this case the MH acceptance probability is close to 1. For example \(h(\gamma_j \mid \boldsymbol{\gamma}_{-j}, \boldsymbol{\beta}_{-j}, \mathbf{y})\) can be based on Laplace approximations to the marginal likelihood, and \(h(\beta_j \mid \boldsymbol{\gamma}, \boldsymbol{\beta}_{-j}, \mathbf{y})\) on a Gaussian approximation to the posterior of \(\beta_j\) under model \(\boldsymbol{\gamma}\) (and given \(\boldsymbol{\beta}_{-j}\)).
3.5 Locally-informed proposals
When devising an MH proposal distribution it is natural to seek that the proposal captures characteristics of the target posterior \(p(\boldsymbol{\eta} \mid \mathbf{y})\). For instance, in Example 3.3 we proposed a new beer tap uniformly among the current neighbors. If most neighbors have low posterior probability, most proposals will be rejected and the chain will get stuck. Intuitively, if one were to propose \(\boldsymbol{\eta}^* \sim p(\boldsymbol{\eta} \mid \mathbf{y})\) then the MH acceptance probability would be 1 and one would draw independent posterior samples from \(p(\boldsymbol{\eta} \mid \mathbf{y})\). Unfortunately one cannot sample from \(p(\boldsymbol{\eta} \mid \mathbf{y})\) (else, MCMC wouldn’t be needed), and in high dimensions it is very hard to devise global approximations \(\hat{p}(\boldsymbol{\eta} \mid \mathbf{y})\) that lead to good MCMC mixing. Locally-informed proposals use (local) information about \(p(\boldsymbol{\eta} \mid \mathbf{y})\) at \(\boldsymbol{\eta}^{(b)}\), where \(b\) is the current iteration. For example, for continuous targets one may use the gradient or hessian of \(\log p(\boldsymbol{\eta} \mid \mathbf{y})\) at \(\boldsymbol{\eta}^{(b)}\) to build the proposal. Popular algorithms along these lines include MALA (Besag (1994), Roberts and Rosenthal (1998), Girolami and Calderhead (2011)) and Hamiltonian Monte Carlo (Section 3.6), both of which use gradients.
In model selection problems the state is discrete, i.e. \(\boldsymbol{\eta}= \boldsymbol{\gamma}\) where \(\boldsymbol{\gamma}\) denotes a model. Here one can use local information by considering models \(\boldsymbol{\gamma}\) that lie in a neighborhood \(\mathcal{N}(\boldsymbol{\gamma}^{(b)})\) of the current \(\boldsymbol{\gamma}^{(b)}\), and set a proposal that is guided by their posterior probability. For example, in variable selection these neighborhoods may be defined by adding or dropping a single parameter to \(\boldsymbol{\gamma}^{(b)}\) (birth-death move), or by exchanging a currently zero by a currently non-zero parameter (swap move). Zanella (2020) studies locally informed proposals for discrete spaces, showing that basing the MH proposal on certain so-called balancing functions enjoys some optimal asymptotic properties. See also Chang and Zhou (2025) for a theoretical analysis of locally-informed algorithms in discrete spaces, establishing conditions in which they lead to dimension-free mixing (spectral gap bounds that don’t depend on the dimension of \(\boldsymbol{\gamma}\)).
An interesting algorithm building on this idea is the locally-informed thresholded (LIT) algorithm of Zhou et al. (2022). The key idea is to propose \(\boldsymbol{\gamma}^* \in \mathcal{N}(\boldsymbol{\gamma}^{(b)})\) with probability \[ h(\boldsymbol{\gamma}^* \mid \boldsymbol{\gamma}^{(b)})= \frac{w(\boldsymbol{\gamma}^*, \boldsymbol{\gamma}^{(b)})}{\sum_{\boldsymbol{\gamma}^* \in \mathcal{N}(\boldsymbol{\gamma}^{(b)})} w(\boldsymbol{\gamma}, \boldsymbol{\gamma}^{(b)})}, \] where \[ w(\boldsymbol{\gamma}, \boldsymbol{\gamma}^{(b)}) = \min \left\{ \max \left\{ \underline{w} , \frac{ p(\boldsymbol{\gamma} \mid \mathbf{y}) }{ p(\boldsymbol{\gamma}^{(b)} \mid \mathbf{y}) } \right\} , \bar{w} \right\}, \] for suitably-chosen \((\underline{w}, \bar{w})\) (and said choice depends on the problem’s dimension \(d\), e.g. \(\underline{w}= 1/d^k\) and \(\bar{w}= d^k\) with \(k=1\) or 2). That is, the probability of proposing \(\boldsymbol{\gamma}\) depends on its posterior odds relative to \(\boldsymbol{\gamma}^{(b)}\), truncated to be in \((\underline{w}, \bar{w})\) (the truncation is needed to avoid the chain getting stuck when transitioning to successively higher probability models).
Intuitively, one expects locally-informed algorithms like LIT to be effective for unimodal target posteriors, such as the first posterior shown in Example 3.3. In fact, the dimension-free results in Zhou et al. (2022) require that the posterior distribution is (rather strongly) concentrated. Fortunately, in Bayesian model selection the posterior distribution on models typically becomes quite concentrated as \(n \to \infty\), and it is also quite concentrated on sparse models when \(n\) is small. Hence, there is hope for locally-informed algorithms to be effective in many applications. This being said, as argued in Example 3.3 if the posterior is strongly multimodal then locally-informed algorithms are expected to work poorly in practice.
Locally-informed proposals can also be embedded within algorithms that allow for larger moves. For example, X. Liang, Livingstone, and Griffin (2023) proposed such an MCMC algorithm for generalized linear and survival models, where the MH proposal proceeds as follows. First, one proposes a new model \(\boldsymbol{\gamma}'\) by randomly adding/dropping each individual variable from the current model \(\boldsymbol{\gamma}^{(b)}\), so that \(\boldsymbol{\gamma}'\) can differ from \(\boldsymbol{\gamma}^{(b)}\) in several included/excluded variables. Second, one proposes a sequence of local moves from \(\boldsymbol{\gamma}'\) that allow reverting some of the changes in \(\boldsymbol{\gamma}'\). The proposal probabilities for these local moves depend on (possibly approximated) model posterior probabilities and balancing functions, and adaptive MCMC is used to set tuning parameters (e.g. birth-death probabilities used in Step 1).
3.6 Hamiltonian Monte Carlo
Hamiltonian Monte Carlo (HMC) is a gradient-based method to sample from continuous distributions, with the appeal that it can propose updates that are far from the current state (i.e. non-local updates). See Neal (2011) for a good review. Two ways how HMC can be used in model selection are as follows. First, once one has approximated the posterior on models \(p(\boldsymbol{\gamma} \mid \mathbf{y})\) (e.g. using another MCMC method), one can sample from \(p(\boldsymbol{\theta} \mid \boldsymbol{\gamma}, \mathbf{y})\) by using HMC to sample the non-zero entries in \(\boldsymbol{\theta}\). Second, HMC can sometimes be used to sample directly from the BMA posterior \(p(\boldsymbol{\theta} \mid \mathbf{y})\), and subsequently sampling from \(p(\boldsymbol{\gamma} \mid \boldsymbol{\theta}, \mathbf{y})\) is trivial because \(\boldsymbol{\gamma}\) is a deterministic function of \(\boldsymbol{\theta}\), e.g. \(\gamma_j = \mbox{I}(\theta_j \neq 0)\). This second use may seem puzzling, because \(p(\boldsymbol{\theta} \mid \mathbf{y})\) is a mixture of continuous and discrete distributions (e.g. the probability that some \(\theta_j\)’s are zero is \(>0\)). M. Xu and Duan (2023) proposed a construction that makes the use of HMC possible. Briefly, let \(\boldsymbol{\theta}\) be the whole set of parameters across all models, e.g. \(p\) regression coefficients. M. Xu and Duan (2023) proposed running HMC on an augmented continuous parameter space \(\tilde{\boldsymbol{\theta}}\), such that the original parameters \(\boldsymbol{\theta}\) are obtained by projecting \(\tilde{\boldsymbol{\theta}}\) into \(L_1\) balls. This projection gives positive posterior probability of having zeroes in \(\boldsymbol{\theta}\). Two appealing properties of this approach is that one may use probabilistic programming languages like STAN or Numpyro, and that one doesn’t need to compute marginal likelihoods \(p(\mathbf{y} \mid \boldsymbol{\gamma})\). There is no guarantee that the chain will mix well, however. In our experience, if marginal likelihoods are cheap to approximate then it is preferable to sample directly from \(p(\boldsymbol{\gamma} \mid \mathbf{y})\) (as discussed in the previous sections), and then from \(p(\boldsymbol{\theta} \mid \boldsymbol{\gamma})\) using whatever sampler is convenient.
We next review the HMC basics. The goal is to sample from \(p(\beta \mid \mathbf{y})\), where \(\boldsymbol{\eta} \in \mathbb{R}^d\). The main trick is to introduce artificial momentum variables \({\bf v} \in \mathbb{R}^d\) that are independent from \(\boldsymbol{\eta}\), such that \[\begin{align} p(\boldsymbol{\eta}, {\bf v} \mid \mathbf{y})= p(\boldsymbol{\eta} \mid \mathbf{y}) N({\bf v}; {\bf 0}, M) \nonumber \end{align}\] for some matrix \(M\) (typically taken to be diagonal). One then produces samples from \(p(\boldsymbol{\eta}, {\bf v} \mid \mathbf{y})\) and therefore also from \(p(\boldsymbol{\eta} \mid \mathbf{y})\) (by discarding the generated \({\bf v}\)’s).
In a nutshell, HMC first updates the momentum variables \({\bf v}\) to a noisy version of the gradient \(\nabla_\eta \log p(\boldsymbol{\eta} \mid \mathbf{y})\) evaluated at the current value of \(\boldsymbol{\eta}\), and next deterministically updates \(\boldsymbol{\eta}\) in the direction of the momentum. The process is repeated \(L\) steps, where the momentum is deterministically updated based on the new gradient, and \(\boldsymbol{\eta}\) updated based on the new momentum. The algorithm is given below.
Hamiltonian Monte Carlo.
Let \(L \geq 1\) and \(\epsilon > 0\) be tuning parameters. Initialize \(\boldsymbol{\eta}^{(0)}\), set \(b=1\).
Sample \({\bf v}^{(b)} \sim N({\bf 0}, M)\)
Deterministic proposal. Set \((\boldsymbol{\eta}^*,{\bf v}^*)= (\boldsymbol{\eta}^{(b-1)}, {\bf v}^{(b)})\). Repeat \(L\) times:
\({\bf v}^*= {\bf v}^* - \frac{\epsilon}{2} \nabla_{\boldsymbol{\eta}} \log p(\boldsymbol{\eta}^* \mid \mathbf{y})\)
\(\boldsymbol{\eta}^*= \boldsymbol{\eta}^* + \epsilon M^{-1} {\bf v}^*\)
\({\bf v}^*= {\bf v}^* - \frac{\epsilon}{2} \nabla_{\boldsymbol{\eta}} \log p(\boldsymbol{\eta}^* \mid \mathbf{y})\)
- Set \(\boldsymbol{\eta}^{(b)}= \boldsymbol{\eta}^*\) with probability \(\min \{1, u\}\) \[\begin{align} u= \frac{p(\mathbf{y} \mid \boldsymbol{\eta}^*) p(\boldsymbol{\eta}^*)}{p(\mathbf{y} \mid \boldsymbol{\eta}^{(b-1)}) p(\boldsymbol{\eta}^{(b-1)})} \nonumber \end{align}\]
HMC has two tuning parameters, the number of steps \(L\) and the step size \(\epsilon\). HMC originated from physics, more specifically a set of partial differential equations called Hamiltonian dynamics. These are hard to solve analytically, instead HMC uses a discretization (the Leapfrog method) based on the chosen \((L,\epsilon)\). Regarding \(\epsilon\), it can be shown that as \(\epsilon \rightarrow 0\) the acceptance probability \(u\) approaches 1, hence in practice one sets a small \(\epsilon>0\). Note also that \(u\) does not require evaluating the ratio of MH proposals densities, which simplifies calculations, this is because it can be shown that such ratio is equal to 1. Regarding \(L\), the most popular HMC algorithm is the so-called no U-turn sampler (Hoffman and Gelman 2014), which sets \(L\) automatically, and is used by the STAN and numpyro softwares.
3.7 Exercises
Exercise 3.1 Consider a MH algorithm that proceeds as the random search algorithm described in 3.3. At the start of iteration \(b\) one knows the current model \(\boldsymbol{\gamma}^{(b-1)}\), and proposes \(\boldsymbol{\gamma}^*\) randomly from \(\mathcal{N}(\boldsymbol{\gamma}^{(b-1)})\), the set of neighbors of \(\boldsymbol{\gamma}^{(b-1)}\).
Show that the MH algorithm sets \(\boldsymbol{\gamma}^{(b)}=\boldsymbol{\gamma}^*\) with probability \[ \min \left\{1, \frac{s(\boldsymbol{\gamma}^*)}{s(\boldsymbol{\gamma}^{(b-1)})} \right\}, \] and otherwise sets \(\boldsymbol{\gamma}^{(b)}= \boldsymbol{\gamma}^{(b-1)}\).
You may assume that the number of neighbors \(|\mathcal{N}(\boldsymbol{\gamma})|\) is the same for all \(\boldsymbol{\gamma}\), and that for any two models \((\boldsymbol{\gamma},\boldsymbol{\gamma}')\), \(\boldsymbol{\gamma}\) is a neighbor of \(\boldsymbol{\gamma}'\) if and only if \(\boldsymbol{\gamma}'\) is a neighbor of \(\boldsymbol{\gamma}\).
First note that the proposal distribution is \[ h(\boldsymbol{\gamma} \mid \boldsymbol{\gamma}^{(b-1)}) = \frac{1}{|\mathcal{N}(\boldsymbol{\gamma}^{(b-1)})|}. \] Hence the MH acceptance probability is the minimum between 1 and \[\begin{align*} \frac{s(\boldsymbol{\gamma}^*)}{s(\boldsymbol{\gamma}^{(b-1)})} \frac{h(\boldsymbol{\gamma}^* \mid \boldsymbol{\gamma}^{(b-1)})}{h(\boldsymbol{\gamma}^{(b-1)} \mid \boldsymbol{\gamma}^*)}= \frac{s(\boldsymbol{\gamma}^*)}{s(\boldsymbol{\gamma}^{(b-1)})} \frac{|N(\boldsymbol{\gamma}^{(b-1)})|}{|N(\boldsymbol{\gamma}^*)|} \end{align*}\] which gives the desired result, since \(|N(\boldsymbol{\gamma}^*)|= |N(\boldsymbol{\gamma}^{(b-1)})|\) by assumption.
Exercise 3.2 Consider a Metropolis-Hasting with target distribution \(\pi(z)\) and proposal \(h(z, z')\). The transition kernel is \[ Q(z, z')= h(z, z') \alpha(z, z') + r(z) \delta_z(z'), \] where \(\alpha(z,z')\) is the MH acceptance probability for a proposed \(z'\), \(\delta_z(z')\) is a point-mass at \(z\), and \[ r(z) = 1- \int h(z,z') \alpha(z,z') dz' \] is the probability of staying at \(z\).
Show that if \(z \sim \pi(z)\), for any set \(A\) the probability that \(z' \in A\) is equal to \(\pi(A)\), i.e. that \(\pi\) is a stationary distribution for \(Q\). You may use that MH satisfies the detailed-balance (or reversibility) condition \[ \pi(z) h(z, z') \alpha(z,z') = \pi(z') h(z', z) \alpha(z', z'). \]
The goal is to show that \[ \int \int \pi(z) Q(z,z') \mbox{I}(z' \in A) dz dz' = \pi(A), \] where \(dz\) and \(dz'\) denote an integral with respect to a suitable dominating measure. Plugging in the expression for \(Q(z,z')\) and using Fubini to exchange the order of the integrals, the left-hand side integral is equal to \[\begin{align} &\int \int \pi(z) \left[ h(z, z') \alpha(z, z') + r(z) \delta_z(z') \right] \mbox{I}(z' \in A) dz dz' \nonumber \\ = &\int \int \pi(z) h(z, z') \alpha(z, z') \mbox{I}(z' \in A) dz dz' + \int \pi(z) r(z) \int \mbox{I}(z' \in A) \delta_z(z') dz' dz \nonumber \\ = &\int \pi(z') \mbox{I}(z' \in A) \left[ \int h(z', z) \alpha(z', z) dz \right] dz' + \int \pi(z) r(z) \mbox{I}(z \in A) dz \nonumber \\ = &\int \pi(z') \mbox{I}(z' \in A) [ 1 - r(z')] dz' + \int \pi(z) r(z) \mbox{I}(z \in A) dz \nonumber \\ = &\int \pi(z) \mbox{I}(z \in A) [ 1 - r(z)] dz + \int \pi(z) r(z) \mbox{I}(z \in A) dz = \int \pi(z) \mbox{I}(z \in A) dz= \pi(A), \end{align}\] as we wished to prove. The key step is in the second equality above where we used reversibility. In the third equality we used the definition of \(r(z')\).
Exercise 3.3 Consider a MH algorithm with proposal distribution \(\eta_j^* \sim p(\eta_j \mid \boldsymbol{\eta}_{-j}^{(b)}, \mathbf{y})\), where \(\boldsymbol{\eta}_{-j}^{(b)}\) is the current value of the remaining parameters. Show that the MH acceptance probability is 1.
The acceptance probability is the minimum between 1 and \[ \frac{p(\eta_j^* \mid \boldsymbol{\eta}_{-j}^{(b)}, \mathbf{y})}{p(\eta_j^{(b)} \mid \boldsymbol{\eta}_{-j}^{(b)}, \mathbf{y})} \frac{p(\eta_j^{(b)} \mid \boldsymbol{\eta}_{-j}^{(b)}, \mathbf{y})}{p(\eta_j^* \mid \boldsymbol{\eta}_{-j}^{(b)}, \mathbf{y})}= 1. \]